

 10 500
10 500 - Что такое Data Science
- Принцип работы Data Science
- Сферы применения Data Science
- Кто такой специалист по Data Science
- Задачи специалиста по Data Science
- Основные инструменты Data Science
- Знания и умения, необходимые для старта в Data Science
-
 Пройди тест и узнай, какая сфера тебе подходит:
Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Data science – это сравнительно новая дисциплина в области поиска, хранения и обработки информации. И пусть вас не смущает слово «science», этот инструмент используется повсеместно и к науке имеет определяющее значение, а не связанное. То есть это и есть своего рода наука – работа с данными.
Бизнес активно использует DS для прогнозирования событий, сбора и сегментации целевой аудитории, изучения спроса на те или иные продукты. Подробнее о том, что собой представляет data science, чем занимаются специалисты из этой области и что нужно, чтобы начать работать в этой сфере, вы узнаете из нашего материала.
Что такое Data Science
Data Science — это дисциплина, повышающая полезность данных. Можно найти разные определения этого понятия и в каждом из них будет присутствовать слово «данные». То есть Data Science применяется очень широко.
Это приводит к тому, что деятельность специалиста в этой области сложно дифференцировать: не вполне понятно, чем именно он занимается, работая с данными, ведь они нужны и для создания отчетов, и для прогнозирования спроса в той или иной области, и для построения сложных математических моделей динамического ценообразования, и для настройки поточной обработки данных для высоконагруженных сервисов, работающих в режиме реального времени.

Слово «наука» в названии используется не просто так. Математика для Data Science является базой, анализ данных основан на классическом математическом аппарате: теории оптимизации, линейной алгебре, математической статистике и не только. Однако наука является фундаментом, а не основной областью деятельности специалистов, большинство из которых занимаются не теорией, а практикой, решают конкретные проблемы.
Сегодня бизнесу хочется в первую очередь понимать, какой положительный эффект может оказать на него Data Science. Важно не то, как строятся модели с помощью алгоритмов машинного обучения, а почему вообще возникла потребность в их создании, как она была сформулирована в математическом ключе и реализована в конкретных способах решения задач.
Огромное значение имеет и проведение честных экспериментов, которые помогают правильной оценке эффективности примененных моделей работы в конкретном бизнесе.
Принцип работы Data Science
Рассмотрим теоретические основы науки о данных. Data science в русскоязычной среде просто транслитерируется – «дата сайенс». Это понятие понимается как совокупность ряда взаимосвязанных дисциплин и методов из области информатики и математики.
входят в ТОП-30 с доходом
от 210 000 ₽/мес

Скачивайте и используйте уже сегодня:


Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда

Подборка 50+ бесплатных нейросетей для упрощения работы и увеличения заработка
Только проверенные нейросети с доступом из России и свободным использованием
ТОП-100 площадок для поиска работы от GeekBrains
Список проверенных ресурсов реальных вакансий с доходом от 210 000 ₽
Первая часть: data
В науке о данных сами данные очевидно занимают определяющее значение. Особое значение имеют методы их сбора, хранения, обработки, а также вычленения из общего массива данных полезной информации. Процесс получения этой выжимки занимает до 80 % рабочего времени специалистов этой области.
Существуют данные, которые не могут быть собраны и обработаны традиционными способами в виду их большого объема и/или разнообразия – их называют большими данными, или big data.
Рассмотрим это на примере.
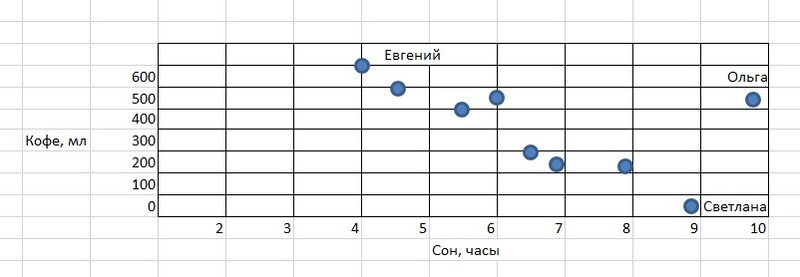
Попробуем проследить взаимосвязь между количеством чашек кофе, которые пьют сотрудники компании в течение дня, и тем, сколько они спали этой ночью. Имеется доступная информация: менеджер Евгений спал накануне 4 часа, после чего выпил 3 чашки кофе, Светлана спала 9 часов и не выпила ни одной чашки кофе, а Ольга спала 10 часов, но выпила 2,5 чашки кофе. Данные можно собирать по всем сотрудникам при необходимости.
Построим график на основе полученной информации о сне менеджеров и выпитых ими чашках кофе (кстати визуализация является важной составляющей любого data science-проекта). Ось X – это время в часах, ось Y – кофе в миллилитрах. Получим такой результат:
Вторая часть: science
Полученные данные нужно каким-то образом обработать, построенный график по идее должен привести нас к конкретным выводам. Для этого информацию следует проанализировать, извлечь из нее полезные закономерности и затем использовать. И вот тут активируется вторая часть data science, а именно такие дисциплины, как статистика, машинное обучение, оптимизация.
Благодаря им и формируется анализ данных. Машинное обучение обеспечивает поиск закономерностей в имеющихся данных, для того чтобы в дальнейшем иметь возможность предсказывать нужную информацию для новых объектов.
В нашем примере мы видим некоторую взаимосвязь между количеством сна и потребностью в кофе: чем меньше сна, тем больше хочется взбодриться тонизирующим напитком. Однако Ольга, которая и спит хорошо, и кофе очень любит, является исключением из общей картины. При этом мы все равно должны попытаться отразить закономерность общей прямой линией таким образом, чтобы она максимально близко подходила ко всем точкам.
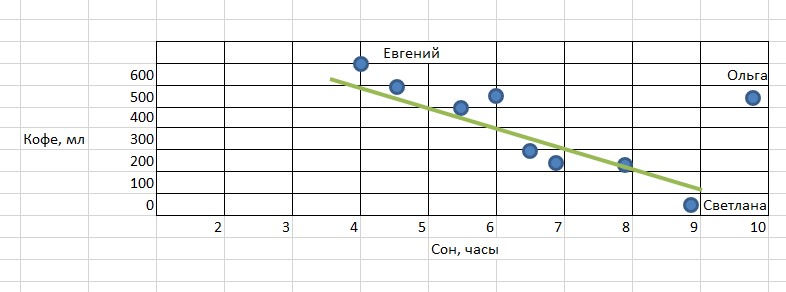
Зеленая линия представляет собой модель машинного обучения, она обобщает данные и имеет математическое описание. Пользуясь этой моделью, можно определять значения для новых объектов. То есть зная, что новый сотрудник Сергей спал сегодня 7,5 часов, мы сможем предсказать, что в течение дня он выпьет около 300 мл кофе. Для этого просто подставим значение в модель. Красная точка – это наше предсказание.
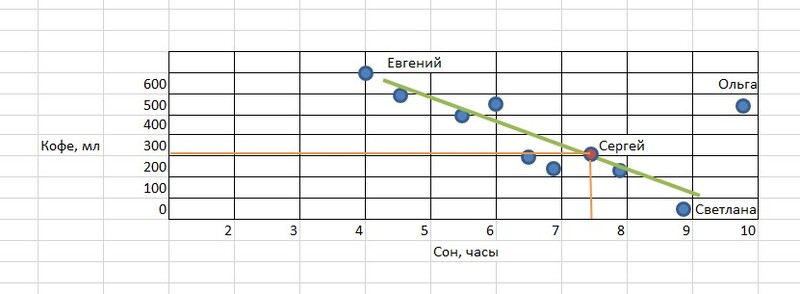
Основная идея машинного обучения довольно проста: обнаружить закономерность и применить ее к новым данным. Но существует еще одна группа ключевых задач, которая имеет целью не предсказание каких-то значений, а разбивку данных на некоторые группы.
Data science-проект является прикладным исследованием, в котором обязательны такие этапы, как постановка гипотезы, разработка плана эксперимента и оценка результата его пригодности для решения определенной задачи. Это имеет огромное значение в сфере бизнеса, когда необходимо понять, будет ли польза от принятия конкретного решения.
Если вернуться к нашему примеру с кофе, то по результатам исследования можно было бы определить количество напитка, которое требуется сотрудникам офиса в течение месяца, и сделать закупку в соответствие с реальными потребностями людей. Однако проведя расчеты, необходимо сравнить полученную модель с уже существующей и выявить лучшую.
Скачать файлДаже в этом примере можно было бы построить более сложный и точный график, учитывающий, например, любовь к кофе каждого отдельного сотрудника, а также другие параметры. А модель могла бы находить более сложные взаимосвязи и представлять собой не прямую линию, а что-то иное. Допустим, Ольга – явное исключение из правила, и она могла стать так называемым выбросом, то есть объектом, отличающимся от остальных.
Такие объекты негативно влияют на процесс построения модели и ее качество, их нужно обрабатывать иначе. А бывает и так, что именно они имеют первостепенную важность для исследования. Это происходит, например, при обнаружении нестандартных банковских операций с целью предотвращения мошенничества.
Как бы хорошо не были собраны и проанализированы данные, всегда есть исключения, нарушающие идеальную целостность полученной картины.
Сферы применения Data Science
По данным компании Kaggle, которая представляет собой профессиональную социальную сеть для специалистов описываемой нами области, сегодня data science аналитика используется бизнесом любого масштаба. IDC и Hitachi отмечают, что 78% предприятий подтверждают серьезный рост количества анализируемой и используемой информации за последнее время.

Предприниматели отдают себе отчет в важности информации и необходимости ее структурирования с целью положительного влияния на собственную деятельность независимо от ее направленности. Перечислим отрасли, в которых Data Science активно используется для решения текущих задач:
- онлайн-торговля и развлекательные сервисы: рекомендательные системы для пользователей;
- здравоохранение: прогнозирование заболеваний и рекомендации по сохранению здоровья;
- логистика: планирование и оптимизация маршрутов доставки;
- digital-реклама: автоматизированное размещение контента и таргетирование;
- финансы: скоринг, обнаружение и предотвращение мошенничества;
- промышленность: предиктивная аналитика для планирования ремонтов и производства;
- недвижимость: поиск и предложение наиболее подходящих покупателю объектов;
- госуправление: прогнозирование занятости и экономической ситуации, борьба с преступностью;
- спорт: отбор перспективных игроков и разработка стратегий игры.
Это далеко не полный список областей и способов применения дата сайенс. Количество кейсов абсолютно разной направленности с использованием «науки о данных» растет год от года.
С Data Science сталкиваются не только специалисты, работающие в этой области, но и простые пользователи интернет-сайтов и сервисов. Это связано с тем, что в них применяются инструменты науки о данных. Допустим, известный аудио-сервис Spotify использует их в рамках оптимизации подбора музыкальных композиций для пользователей в соответствии с их предпочтениями.
Это касается и видео-стримингов вроде Netflix, которые стараются предложить своим зрителям релевантный их интересам контент. Uber активно изучает данные, для того чтобы прогнозировать спрос, повышать качество своих продуктов, автоматизировать рабочие процессы.
 ТОП-100 площадок для поиска работы от GeekBrains
20 профессий 2023 года, с доходом от 150 000 рублей
Чек-лист «Как успешно пройти собеседование»
ТОП-100 площадок для поиска работы от GeekBrains
20 профессий 2023 года, с доходом от 150 000 рублей
Чек-лист «Как успешно пройти собеседование»
Рассчитывать исключительно на результаты Data Science не стоит, однако в ней есть крайне полезные инструменты, которые позволяют бизнесу лучше ориентироваться в своей сфере и примерно прогнозировать будущее.
Кто такой специалист по Data Science
Датасаентист – это специалист, который занимается обработкой массива данных, извлечением из них полезной информации, нахождением взаимосвязей и закономерностей, используя алгоритмы машинного обучения. Модель представляет собой алгоритм, который можно использовать для решения бизнес-задач.
Например, в Яндекс.Такси модели создаются для прогнозирования спроса, подбора оптимальных маршрутов, контроля состояния водителей. Удачное использование моделей позволяет снижать стоимость поездок и повышать качество услуг. В банковской сфере с помощью модели можно оптимизировать процесс принятия решения о выдаче кредита потенциальному заемщику.
В страховых компаниях они помогают оценивать вероятность наступления страхового случая. Тем, кто продает свои товары онлайн, внедрение модели может помочь увеличить рекламную конверсию.
Следует отличать датасаентиста от аналитика данных. Аналитик data science в процессе своей работы анализирует информацию и в результате выдает модель или код, написанный на основе этого анализа. Его основная задача лежит в технической плоскости, он скорее инженер. Аналитик данных занимается решением бизнес задач, для чего он изучает нужды потребителей, анализирует информацию, тестирует гипотезы и визуализирует результат.
Датасаентист работает с помощью машинного обучения. Он создает модель по выданному ему техническому заданию. Она должна обеспечить определенный результат.
Задачи специалиста по Data Science
Data science аналитик данных в каждой компании имеет свои задачи. В крупных корпорациях он, как правило, отвечает за несколько направлений деятельности. Если это банк, датасаентист может заниматься вопросами оценки заемщиков и распознавания речи.
Рассмотрим стандартные этапы рабочего дня специалиста в области Data Science. Как правило, их пять.
- Сбор информации. Информация разного рода (структурированная и неструктурированная) собирается из разных источников, которые являются релевантными поставленной задаче и области деятельности. Методы работы разнообразны – это и ручной ввод, и скрапинг веб-страниц, и сбор данных из проприетарных систем.
- Хранение информации. Специалист ищет способы хранения собранной информации, которые позволят в дальнейшем заняться ее обработкой с использованием уже имеющихся специальных инструментов. На этом этапе происходит фильтрация данных, удаление дублей и т.п.
- Предобработка. Происходит предварительный анализ собранных данных и выявление наиболее заметных взаимосвязей между ними. Кроме того, на этом этапе необходимо проследить паттерны, проверить реальность информации и ее соответствие решаемым задачам.
- Обработка. Собранные данные обрабатываются с помощью специальных инструментов датасаентиста. Он использует искусственный интеллект, модели машинного обучения, аналитические алгоритмы и т.д.
- Коммуникация. Специалист визуализирует результаты работы, создавая таблицы, графики, списки и т.п. Форма подачи данных выбирается в зависимости от конкретной ситуации, выполняемых задач и категории потребителей информации.
Читайте также!

Несмотря на то, что работа датасаентистов в каждой сфере деятельности строится по определенным уникальным правилам, есть и общие для всех областей черты. Практически каждый специалист должен:
- определить задачи, которые хочет решить заказчик;
- выяснить, насколько целесообразно решать рабочий вопрос с использованием методов машинного обучения;
- собрать, обработать данные, разметить, подготовить их к дальнейшему использованию;
- определить метрики оценки эффективности модели;
- разработать и протестировать модели машинного обучения;
- доказать прогнозируемый экономический эффект от внедрения модели;
- внедрить модель в бизнес-процессы;
- сопровождать модель в процессе ее использования.
Использовать инструменты Data Science можно в рамках бизнеса любого масштаба. Разница в размерах команды и масштабе решаемых задач. Основной объем работы – у руководителя проекта. Он поддерживает контакт с заказчиками, получает четкое ТЗ, а потом ставит задачи подчиненным (аналитикам разного уровня). Датасаентист, работающий в одиночку, может и общаться с заказчиками, и выполнять поставленные перед ним задачи.
Собирать данные также могут как несколько специалистов, так и один – все зависит от уровня компании и масштабов отдела аналитики. При этом как правило используются инструменты, упрощающие и автоматизирующие этот процесс. Они также помогают предварительно фильтровать и систематизировать полученную информацию.
Довольно частая ситуация – получение разрозненной информации от заказчика. Ее нужно обработать, структурировать, найти взаимосвязи и закономерности. Для этого нередко используется пайплайн — стандартная последовательность действий в ходе анализа данных. У каждого специалиста она своя.
Как правило, в процессе считывания информации аналитик выдвигает гипотезы, которые потом нужно проверять. Данные необходимо перевести в формат, удобный для машинного обучения. Это позволяет запустить «пробное» обучение и проверить выдвинутые гипотезы. Если они не подтверждаются, этот набор данных больше не используется в работе.





Когда какая-то гипотеза (или несколько гипотез) находит подтверждение, получается первая (baseline, или базовая) версия модели. На ней будут строиться последующие итерации, которые могут привести к улучшению самой модели. Это тот продукт, который уже можно продемонстрировать заказчику, протестировать и развивать дальше.
Создавая модель, определяют и метрики, позволяющие впоследствии оценить ее эффективность. Как правило, создают два типа метрик: для бизнеса и технические. Первые дают возможность отследить экономический эффект от внедрения модели, а вторые определяют ее качество (допустим, точность предсказаний).
Тестирование имеет огромное значение, так как модель с ошибками может повлечь серьезные проблемы для бизнеса. Так, использование неправильной скоринговой модели приведет к одобрению кредитов людям, которые не имеют возможности систематически возвращать долг. В итоге банк понесёт убытки.
Основные инструменты Data Science
Специалисты Data Science должны иметь теоретическую и практическую подготовку в области программирования и создания приложений, поскольку это расширяет их профессиональный инструментарий и рабочие возможности. Важно знать хотя бы один из двух самых популярных в Data Science языков программирования.
- R. Это язык с открытым исходным кодом и программное окружение для создания статистических вычислений. В нем содержится множество библиотек и удобных инструментов, позволяющих фильтровать данные и совершать их предварительную обработку. R предоставляет широкие возможности для визуализации данных и тестирования созданной модели машинного обучения.
- Python. Универсальный язык объектно-ориентированного программирования. Python data science можно использовать в самых разных направлениях деятельности для работы с данными практически любого формата.

Стоит также упомянуть о таких инструментах датасаентистов, как Apache Spark, Tableau, Microsoft PowerBI. И перечислять их можно еще долго.
Знания и умения, необходимые для старта в Data Science
Сегодня основы data science можно изучить на многочисленных курсах и с помощью профильных книг. Специалист в этой области должен иметь довольно обширные знания в области точных наук, машинного обучения, языков программирования, сбора данных.
Статистика, математика, линейная алгебра
Data science обучение предполагает изучение базового курса теории вероятностей, математического анализа, линейной алгебры и математической статистики. Это необходимо для осуществления грамотного анализа результатов применения алгоритмов обработки данных.
Литература.
- «Практическая статистика для специалистов Data Science», П. Брюс, Э. Брюс. Книга актуальна тем, кто уже знаком со статистикой.
- «Наука о данных с нуля», Дж. Грас. Книга поможет в сжатые сроки освоить новую профессию. Из нее можно почерпнуть знания в области большинства необходимых датасаентисту дисциплин.
- «Нейронные сети. Полный курс», С. Хайкин. Работа, посвященная математической составляющей нейросетей.
Машинное обучение
Машинное обучение, или data science machine learning, дает возможность настроить компьютеры таким образом, чтобы они принимали решения в автономном и автоматическом режиме.
Для освоения Data Science с нуля необходимо изучить три главных раздела машинного обучения.
- Обучение с учителем (Supervised Learning). Дает возможность создать прогноз по заранее размеченным данным. В случае, когда нужно предсказать несколько значений (допустим, отличить изображения парусников от автомобилей и катеров), это задача классификации, а если одно (например, предположить стоимость автомобиля в зависимости от его характеристик) — задача регрессии.
- Обучение без учителя (Unsupervised learning). В данном случае отсутствует разметка данных, результат и способ обработки данных заранее не известны. Так можно искать аномалии (нестандартные транзакции по банковской карте), ошибочные показания датчиков и т.п.
- Обучение с подкреплением (Reinforcement learning). Здесь тоже нет разметки, однако присутствует стимулирование нейросети (положительное или отрицательное) в ответ на какие-то действия. Например, таким образом машины обучаются игре в компьютерные игры вроде Dota 2 или Starcraft II.
Литература.
- «Машинное обучение. Наука и искусство построения алгоритмов, которые извлекают знания из данных» П. Флах. Это книга о методах построения моделей и алгоритмах машинного обучения.
- «Вероятностное программирование на Python: байесовский вывод и алгоритмы», К. Дэвидсон-Пайлон. Работа об алгоритмах обработки данных и развитии аналитического мышления и навыков.
- «Введение в машинное обучение с помощью Python», А. Мюллер, С. Гвидо. Книга заточена на отработку практических навыков МО.
Программировать на Python
Data science machine напрямую связана с программированием. Специалисту в области аналитики данных вполне достаточно (по крайней мере на первых порах) знать один язык и лучше всего начать с Python. Это универсальный и многофункциональный язык с простым синтаксисом, который часто используется для обработки данных.
Литература.
- «Python для сложных задач. Наука о данных и машинное обучение», Дж. Вандер Плас. Книга представляет собой руководство по статистическим и аналитическим методам обработки данных.
- «Python и анализ данных», Уэс Маккинни. Автор рассказывает о применения языка программирования Python в дата сайенс.
- «Автоматизация рутинных задач с помощью Python», Эл Свейгарт. Хорошее пособие для новичков.
- «Изучаем Python», М. Лутц. Универсальный учебник с упором на практику. Подойдет и тем, кто только начинает свой путь в работе с данными, и опытным разработчикам.
Основные библиотеки:
- Numpy
- Scipy
- Pandas
Визуализация:
- Matplotlib
- Seaborn
Читайте также!

Машинное обучение и глубокое обучение:
- SciKit-Learn
- TensorFlow
- Theano
- Keras
Обработка естественного языка:
- NLTK
Веб-скрейпинг:
- BeautifulSoup 4
Собирать данные
Data Mining — серьезный аналитический процесс, в рамках которого происходит изучение данных. С его помощью можно выявлять скрытые паттерны и таким образом получать новую полезную информацию, которая нужна для принятия решений. Тут речь также идет о визуализации данных.
Литература
- «Технологии анализа данных: Data Mining, Visual Mining, Text Mining, OLAP» В.В. Степаненко, И.И. Холод. В книге приведены основные методы обработки данных с примерами.
- «Data mining. Извлечение информации из Twitter, LinkedIn, GitHub», М. Рассел. М. Классен. Пособие по анализу данных на примере социальных сетей с практическими советами.
Тем, кто заинтересовался сферой Data Science, имеет смысл пройти профильные курсы в онлайн режиме – например, в школе GeekBrains – после чего отправиться на стажировку в компанию для получения практических навыков.

Прежде чем искать работу, можно поучаствовать в открытых проектах или соревнованиях. Это позволит определить свой уровень знаний и умений и протестировать профессиональные навыки.


 0
0 











 Разберем 11 самых важных жизненных вопросов
Разберем 11 самых важных жизненных вопросов







Статья очень хорошо раскрыта, к тому же с конкретными примерами) спасибо